{kind=link}
Diseño, entorno y aprobación ética del estudio.
Este es un estudio de cohorte retrospectivo multicéntrico que utiliza datos de registros nacionales recopilados prospectivamente del Registro COVID-19 de Japón (COVIREGI-JP), operado bajo el proyecto Repositorio de datos y muestras biológicas de enfermedades infecciosas (REBIND) encargado por el Ministerio de Salud, Trabajo y Bienestar de Japón. En agosto de 2023, 677 hospitales participaron en COVIREGI-JP. Los datos de los pacientes se registraron en Analysis Digital Knowledge Seize, una aplicación de captura de datos basada en net alojada en el centro de datos del Centro Conjunto para Investigadores, Asociados y Médicos del Centro Nacional de Salud y Medicina World. Los datos utilizados fueron proporcionados por COVIREGI-JP y el proyecto de estudio fue aprobado por el Comité de Ética del instituto de investigación (TEG-01791-012) luego de que se cargó un documento sobre una política de exclusión voluntaria para todos los sujetos y/o sus familiares. en el sitio net del instituto. Se renunció al consentimiento informado por escrito porque la recopilación de datos se realizó sin ninguna intervención y la gestión de los datos se procesó de forma anónima. Todos los procedimientos de investigación se realizaron de acuerdo con la Declaración de Helsinki.
Participantes
Los participantes elegibles incluyeron todos los pacientes adultos (edad ≥ 18 años) diagnosticados con COVID-19 mediante una prueba rápida de antígeno del SARS-CoV-2 o una prueba de reacción en cadena de la polimerasa y admitidos en el hospital. Se excluyeron los pacientes que utilizaban anticoagulantes y aquellos que carecían de datos para el diagnóstico de CID al ingreso (día 1). En el primer análisis, los pacientes incluidos se dividieron en grupos con CID y sin CID para el análisis al momento del ingreso. En el segundo análisis, se excluyeron aún más los pacientes sin datos continuos para el diagnóstico de CID desde el día 1 al 15. Aquellos con datos continuos completos para el diagnóstico de CID se dividieron en grupos con y sin CID según el diagnóstico de CID en cualquiera de los días del 1 al 15. El período de inscripción del presente estudio fue del 1 de enero de 2020 al 31 de diciembre. , 2021. El diagrama de flujo de la inclusión y exclusión de pacientes se muestra en la Fig. 1.
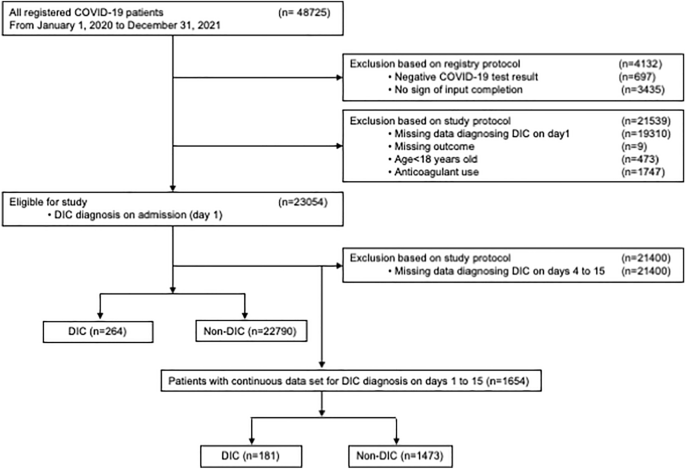
Diagrama de flujo de inclusión y exclusión del estudio.
Diagnóstico y definición.
Se realizó un diagnóstico de CID según los criterios de diagnóstico de CID de la Asociación Japonesa de Medicina Intensiva (JAAM).15 (Figura complementaria. 1). En este estudio, el tiempo de protrombina/cociente internacional normalizado (INR) sirvió como sustituto del cociente de tiempo de protrombina en el diagnóstico de CID. En los casos en los que faltaban datos de fibrinógeno/productos de degradación de fibrina (FDP), se utilizaron niveles de dímero D como sustituto. El síndrome de respuesta inflamatoria sistémica (SIRS) y el SOFA rápido (qSOFA) se calcularon utilizando las definiciones del American Faculty of Chest Physicians/Society of Important Care Drugs y Sepsis-3, respectivamente.11,dieciséis. La definición de Berlín se utilizó para el diagnóstico y la clasificación de gravedad del síndrome de dificultad respiratoria aguda (SDRA).17. La gravedad de la hipoxemia de los pacientes se definió de la siguiente manera: leve, SpO2≥ 94% bajo aire ambiente; moderada, SpO22< 94 % con aire ambiente o necesidad de oxígeno a cualquier caudal, incluida la oxigenación nasal de alto flujo; y grave, uso de ventilación invasiva o no invasiva u oxigenación por membrana extracorpórea (ECMO). El shock se definió como una presión arterial media inferior a 65 mmHg al ingreso. La disfunción orgánica se diagnosticó el día 4 y las definiciones fueron las siguientes: sistema nervioso central, alerta, responder a la voz, responder al dolor, no responder (AVPU) escala ≥ 118; pulmón, utilice cualquiera de los siguientes tratamientos (oxígeno, oxígeno de alto flujo nasal, ventilación invasiva y no invasiva, ventilación en decúbito prono, óxido nítrico, traqueotomía, relajante muscular, oxigenación por membrana extracorpórea [ECMO]); corazón, uso de catecolaminas o inotrópicos; hígado, bilirrubina complete ≥ 2,0 mg/dl; y riñón, uso de terapia de reemplazo renal o diálisis peritoneal. Más de dos disfunciones orgánicas se definieron como MODS. Se calculó el índice de masa corporal (IMC) y los niveles de obesidad se definieron de la siguiente manera19: peso insuficiente, < 18,5; normales, 18,5 a 24,9; obesidad 1, 25,0–29,9; obesidad 2, 30,0–39,9; y obesidad 3, ≥ 40 kg/m2. Las comorbilidades y complicaciones se diagnosticaron a criterio de los médicos de los institutos participantes.
Recopilación de datos y mediciones.
Los datos de laboratorio sobre signos clínicos y tratamientos se registraron al ingreso (día 1) y los días 4, 8 y 15. Además de las pruebas de laboratorio de rutina, se registraron recuentos de plaquetas, tiempo de protrombina (INR), tiempo de tromboplastina parcial activada (TTPA), fibrinógeno. Se midieron , PDF y dímero D para evaluar los cambios coagulofibrinolíticos y el diagnóstico de CID.
Medidas de resultado
En primer lugar, este estudio determinó la incidencia de CID en COVID-19 en las dos cohortes. La primera cohorte estuvo compuesta por pacientes con COVID-19 diagnosticados con CID al ingreso (día 1), y la segunda cohorte incluyó pacientes con datos de diagnóstico completos de CID desde el día 1 hasta los días 4, 8 y 15 después del ingreso. En la segunda cohorte, los pacientes diagnosticados de CID en cualquiera de los días del 1 al 15 se clasificaron en el grupo de CID. El resultado primario fue la muerte hospitalaria y los resultados secundarios incluyeron el número de disfunción orgánica, la incidencia de MODS, el ingreso a la UCI y la duración de la estancia hospitalaria. Estos resultados se compararon entre pacientes con CID y pacientes sin CID mientras se evaluaban las influencias correspondientes de la CID. Los posibles factores de confusión para evaluar la muerte hospitalaria fueron la edad, el sexo, el IMC, las comorbilidades, el shock, la saturación de oxígeno (SpO2), linfocitos y complicaciones. Al evaluar MODS el día 4, se utilizaron como posibles factores de confusión la edad, el sexo, el IMC, las comorbilidades, el shock, la saturación de oxígeno y los linfocitos. Todos los pacientes fueron seguidos hasta el alta hospitalaria.
Análisis estadístico
Las variables medidas se expresaron como la mediana con el rango intercuartil de 25 a 75 o como número en porcentaje. El tamaño del estudio dependió del período de registro y los valores faltantes se utilizaron sin imputación. Las diferencias en la demografía y los parámetros medidos entre los dos grupos (CID versus no CID) se compararon mediante la prueba U de Mann-Whitney y la prueba exacta de Fisher para variables continuas y nominales, respectivamente. Se construyó la curva de características operativas del receptor (ROC) y el área bajo la curva ROC (AUC) se utilizó para evaluar la capacidad predictiva de las puntuaciones DIC para MODS y muerte intrahospitalaria. Se aplicó el índice de Youden para calcular los valores de corte de sensibilidad y especificidad. Las curvas de probabilidad de supervivencia de pacientes con y sin CID se derivaron según el método de Kaplan-Meier. Se aplicaron modelos de regresión logística univariados y multivariados para obtener odds ratios (OR) crudos y ajustados, respectivamente, y se utilizaron intervalos de confianza (IC) del 95% para confirmar la asociación independiente entre CID con muerte hospitalaria y MODS el día 4. Sensibilidad Los análisis se aplicaron con análisis de regresión logística por pasos utilizando el criterio de información de Akaike en el método de eliminación hacia atrás utilizando posibles factores de confusión similares descritos en la sección sobre medidas de resultado. Se utilizó la prueba de Wald para evaluar la importancia de los resultados de los análisis de regresión logística. La prueba de bondad de ajuste de Hosmer-Lemeshow, el issue de inflación de la varianza (VIF) y las distancias de Prepare dinner se utilizaron como estadísticas de diagnóstico para evaluar el ajuste del modelo, la colinealidad y los puntos influyentes, respectivamente, para confirmar la solidez de los análisis de regresión logística.
Diferencias con dos colas. pag-Los valores < 0,05 se consideraron estadísticamente significativos. Para los análisis y cálculos estadísticos se utilizó R (versión 4.2.3; Un lenguaje y entorno para la informática estadística. Fundación R para la informática estadística, Viena, Austria).